May 24, 2025 · essay
To RAG or Not to RAG? Navigating Million-Token Context Windows in Modern AI
With LLMs boasting million-token context windows, is RAG still necessary? Explore when to 'just stuff it in' versus when advanced RAG techniques are crucial for truly intelligent AI.

The short version
- LLM
- This post explores the evolving role of Retrieval Augmented Generation (RAG) in an era of LLMs with million-token context windows, like Google's Gemini, discussing when direct prompting suffices versus when advanced RAG is still crucial.
- Why
- To help developers and AI strategists decide whether to implement RAG or leverage large context windows for their knowledge base applications, considering factors like data size, complexity, and desired accuracy.
- Challenge
- The advent of massive context windows in LLMs challenges the traditional necessity of RAG for all knowledge-intensive tasks. However, naive RAG has its own limitations when dealing with very large or complex datasets.
- Outcome
- A nuanced understanding that while large context windows simplify interaction with smaller knowledge bases, advanced RAG techniques (like Contextual Retrieval, Agentic RAG, and Knowledge Graphs) are vital for scaling AI capabilities and achieving high accuracy with extensive or intricate data.
- AI approach
- This analysis synthesizes information from multiple sources, including AI research papers and practical implementation guides, to provide a balanced perspective on choosing the right approach for context provisioning in modern AI systems.
- Learnings
- For knowledge bases under ~200k tokens, direct prompting with large context models can be effective. Beyond that, or for higher accuracy, enhanced RAG strategies are necessary to overcome the shortcomings of basic retrieval methods and ensure AI agents can truly leverage comprehensive information.
To RAG or Not to RAG? Navigating Million-Token Context Windows in Modern AI
Introduction: The Context Conundrum in AI
Remember the early days of working with Large Language Models (LLMs)? It feels like a lifetime ago, but it was only recently that we wrestled with severely limited context windows. Trying to get an AI to act as a true domain expert on your company's documents or a specific knowledge base often felt like fitting an elephant into a shoebox. You'd painstakingly craft prompts, feed in a paragraph or two, and inevitably hit a wall, unable to provide the comprehensive background the AI truly needed.
This fundamental limitation catapulted Retrieval Augmented Generation (RAG) into the spotlight. RAG quickly became the go-to strategy for granting AI systems access to your proprietary knowledge. The concept is elegant: break down your extensive knowledge base into digestible chunks, transform them into numerical embeddings, store them in a vector database (like Qdrant, Pinecone, or ChromaDB), and then, when a query comes in, retrieve the most relevant pieces of information to "augment" the LLM's prompt. Suddenly, your AI could converse with surprising expertise about your specific data. Tools like n8n.io have significantly simplified this process, enabling developers to build robust RAG pipelines—for example, by integrating with Google Drive, Gemini, and a Qdrant vector store to create AI-powered RAG chatbots for your documents. For any knowledge base too large to fit wholesale into those early, constrained context windows, RAG wasn't just an option; it was a necessity.
But the AI landscape is nothing if not fast-moving. Now, we're witnessing the arrival of behemoth models like Google's Gemini series, boasting context windows of one million tokens or even more. To grasp the scale, a million tokens can encapsulate the entirety of several novels or hundreds of podcast transcripts. This leap from the 8k, 32k, or even 128k token limits of the recent past—which forced us into complex strategies like message dropping, summarization, or vector database RAG—is monumental.
This new reality begs a crucial question for anyone building AI solutions: With such vast in-prompt capacity, do we still need RAG?
The Evolving Answer: It's All About Scale and Complexity
As with many things in AI, the answer isn't a simple yes or no. It's nuanced, hinging primarily on the size, nature, and complexity of your knowledge base, as well as the accuracy demands of your application.
When "Just Stuff It In" Might Work: The All-in-Prompt Approach
For knowledge bases that are relatively modest – say, under the equivalent of a few hundred pages or roughly 200,000 tokens – the new generation of Large Language Models (LLMs) with extensive context windows offers a tantalizingly simple alternative. You might be able to load the entire relevant knowledge base directly into the prompt. As highlighted in Google's documentation for Gemini's long context capabilities, models like Gemini 1.5 Pro can process up to 1 million tokens (and even up to 10 million in private preview), which is equivalent to around 700,000 words or many hours of video/audio. This allows for what Google calls a "more direct approach: providing all relevant information upfront."
This direct method enables the model to leverage its powerful in-context learning capabilities across your entire dataset simultaneously. When your complete dataset fits comfortably within the model's vast context window, and your queries are relatively straightforward (like finding specific facts or summarizing contained information), this direct method can bypass the need for a separate RAG pipeline entirely, simplifying your architecture. Techniques like caching prompts (if using the API) can further enhance efficiency for repeated queries over the same substantial context, making this approach significantly faster and more cost-effective in those scenarios.
When RAG (and its Smarter Siblings) Still Reigns Supreme
However, as your knowledge base scales beyond what even a million-token window can hold, or when the complexity of information retrieval and synthesis increases, RAG and its more advanced iterations remain indispensable.
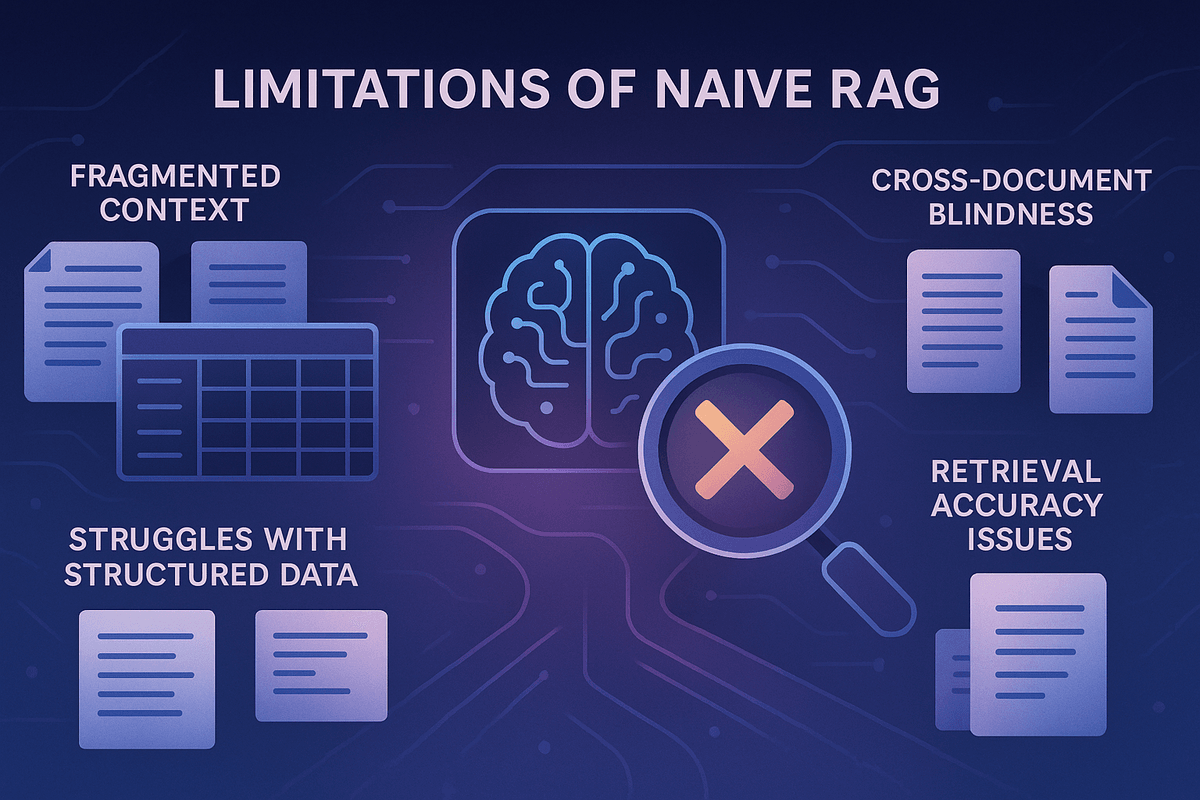
Moreover, even when a large context window could theoretically hold all your data, simply throwing everything at the LLM isn't always the most effective or efficient strategy. And traditional, "naive" RAG implementations have their own well-documented shortcomings, especially when dealing with complex, interconnected information:
- Fragmented Context: RAG typically splits documents into chunks. An individual chunk, retrieved in isolation, might lack crucial surrounding context. A sentence about revenue growth, for example, is meaningless without knowing which company or time period it refers to, information that might reside in an adjacent, unretrieved chunk.
- Struggles with Structured & Tabular Data: Basic RAG often falters when trying to analyze trends in spreadsheets or answer questions requiring aggregation across multiple rows or tables, as it might only retrieve a small, unrepresentative fraction of the data.
- Cross-Document Blindness: Connecting disparate pieces of information scattered across multiple documents to answer a complex query is a significant challenge for simple RAG.
- Retrieval Accuracy Issues: Even getting the right chunks can be problematic. Benchmarks have shown non-trivial failure rates for basic RAG in pulling the most relevant information, which is often unacceptable for production-grade AI solutions.
Simply using a large context window to process the output of a flawed RAG retrieval doesn't fix the underlying issue if the RAG process itself missed vital information or pulled irrelevant snippets. And while LLMs are adept at "needle-in-a-haystack" tasks (finding one piece of info in a long text), their performance can degrade when searching for multiple needles.
Beyond Basic RAG: The Next Level of Intelligent Retrieval
To build truly robust and accurate AI agents that can leverage large, complex knowledge bases, we often need to move beyond naive RAG. The field is rapidly evolving with more sophisticated techniques:
- Contextual Retrieval: This approach, significantly detailed and benchmarked by teams like Anthropic, dramatically boosts retrieval accuracy. The core idea is to enrich data chunks before they are embedded and indexed. An LLM is used to generate a concise, explanatory context for each chunk based on its surrounding document (or even related documents). This generated context is then prepended to the chunk's actual content. When a user query comes in, the retrieval system searches against these context-enriched chunks. This gives the retrieval mechanism a much better understanding of each piece of information and its original significance. Anthropic's research shows that this technique alone can substantially reduce retrieval failures, and when combined with other methods like lexical search (BM25) and reranking, the improvements are even more pronounced. Prompt caching strategies can make the upfront context generation cost-effective.
- Agentic RAG: Instead of RAG being a passive "tool" that an LLM calls, an Agentic RAG system gives the LLM more reasoning capability about the retrieval process itself. The agent can analyze the results of an initial RAG lookup. If it's insufficient (e.g., it needs to analyze a whole spreadsheet, not just a few rows), the agent can decide to use different tools: list available documents by title, retrieve the full content of a specific document, or even query tabular data using SQL-like commands. This adaptability overcomes many limitations of fixed RAG pipelines.
- Hybrid Search: This combines the strengths of semantic search (which understands meaning and context via embeddings) with traditional lexical search (like BM25, which is good at finding exact keyword matches). This fusion ensures that queries for specific technical terms, error codes, or unique identifiers aren't missed by embedding models alone.
- Reranking: In a typical RAG process, an initial retrieval might pull hundreds of potentially relevant chunks. A reranking model (often a smaller, specialized LLM or a cross-encoder) then scores these initial results based on their precise relevance to the user's query. Only the top-K (e.g., the best 20) chunks are then passed to the main LLM for answer generation. This filters noise, improves response quality, and reduces the cost and latency of the final LLM call.
- Knowledge Graphs: For very large and interconnected knowledge bases, Knowledge Graphs are emerging as a powerful complement or alternative to pure vector search. Frameworks like LightRAG construct a graph that maps relationships between topics, ideas, and concepts found within your documents, alongside the traditional vector store. This provides a much deeper contextual understanding. When a query comes in, such systems can leverage both vector retrieval and graph traversal to find the most relevant and interconnected information. This approach shows particular promise as knowledge bases grow exponentially (into thousands or hundreds of thousands of documents), a scale at which naive RAG can start to degrade significantly.
The choice of database technology (vector DBs like Qdrant, Chroma, or hybrid solutions with Postgres) and data processing tools (like Unstructured.io for complex file types) also plays a crucial role in the effectiveness of any RAG system. For real-time, constantly changing data, specialized dynamic knowledge graph solutions are also being developed.
To RAG, Evolve RAG, or Go Direct?
The arrival of million-token context windows in models like Gemini has undeniably shifted the landscape. For smaller, self-contained knowledge bases, the ability to include all relevant information directly in the prompt offers a powerful and simpler path, potentially obviating the need for a separate RAG pipeline.
However, for large, complex, and ever-growing datasets, RAG in some form remains essential for providing scalable access to external knowledge. The key takeaway is that basic RAG is often just the starting point. To build truly intelligent, reliable, and accurate AI agents capable of deeply understanding and utilizing vast knowledge stores, we must embrace more advanced strategies. Contextual Retrieval, Agentic RAG, Hybrid Search, Reranking, and Knowledge Graphs are not just academic curiosities; they are increasingly becoming necessary components for pushing the boundaries of what AI can achieve.
So, the question isn't just "To RAG or not to RAG?" It's also "If RAG, then how RAG?" As your data grows and your accuracy requirements tighten, evolving beyond basic RAG will likely be key to unlocking the full potential of your AI systems.