May 15, 2025 · essay
Powering My Desktop AI Assistant with Web-Scale Knowledge by Integrating Crawl4AI for RAG
Integrating Crawl4AI into an Electron/Vue3 AI assistant to build a powerful, local RAG system, overcoming Playwright challenges with Docker.
The short version
- LLM
- My LLM assistant (Google Gemini 2.5 Pro Preview 05-06) was instrumental in planning the architecture, refactoring Python code for the FastAPI backend, and debugging the Docker/Playwright integration. It helped generate initial Dockerfiles and FastAPI endpoint structures.
- Why
- To significantly enhance my Electron AI assistant by enabling it to ingest knowledge from websites, sitemaps, or text files, and then perform Retrieval Augmented Generation (RAG) queries against this custom knowledge base, moving beyond pre-trained model limitations.
- Challenge
- Integrating Python-based `crawl4ai` (with its Playwright dependency) into a FastAPI backend, especially resolving Playwright's asyncio/subprocess issues on Windows, and then structuring the communication pipeline from Electron -> Main FastAPI -> Dockerized Crawler Service -> Main FastAPI (for RAG) -> Electron.
- Outcome
- A functional RAG backend where the Electron app can trigger data ingestion (crawling via a Dockerized `crawl4ai` service, chunking, vectorization into ChromaDB) and query this knowledge base, all managed by the FastAPI server.
- AI approach
- The LLM acted as a system architect, Python/FastAPI developer, Docker consultant, and debugger. It helped outline the multi-stage backend, draft Pydantic models for API communication, and provided solutions for the complex Playwright-on-Windows-in-FastAPI problem (leading to the Dockerized worker strategy).
- Learnings
- Docker provides excellent isolation for problematic dependencies like Playwright on Windows. FastAPI APIRouters are great for modularizing backend services. Multiprocessing in Python can manage tasks with conflicting asyncio loop requirements. Clear API contracts between services (Electron-FastAPI, FastAPI-DockerCrawler) are crucial.
Why this project? My "Desktop AI Assistant," an Electron/Vue3 AI assistant, was already quite capable with its Ollama, Kokoro TTS, and Whisper integrations. However, its knowledge was limited to the pre-trained models it used. The next logical step was to empower it with the ability to learn from custom data sources – specifically, to crawl websites, sitemaps, or even local text files, and then perform Retrieval Augmented Generation (RAG) against this personalized knowledge. This is where the excellent crawl4AI library came into the picture.
The Challenge(s): The primary goal was to integrate crawl4AI's Python-based crawling and processing capabilities into my existing Python FastAPI backend (which already served Kokoro TTS). The major hurdles were:
- Playwright & Asyncio on Windows: crawl4ai uses Playwright for browser automation. Running Playwright within an asyncio framework like FastAPI (powered by Uvicorn) on Windows proved to be a significant challenge due to a persistent NotImplementedError related to asyncio's subprocess creation. We tried global event loop policies, separate threads, and even separate processes via multiprocessing, but the issue within the main FastAPI process tree remained.
- Architectural Complexity: Designing a robust pipeline: Electron app (client) -> Main FastAPI server (orchestrator) -> Specialized Crawler Service -> Main FastAPI server (for chunking, embedding, RAG) -> Electron app.
- Backend Modularity: Ensuring the new RAG logic within the FastAPI server was well-organized, with clear separation between API routing, orchestration, and core services (ChromaDB, chunking, LLM interaction for RAG).
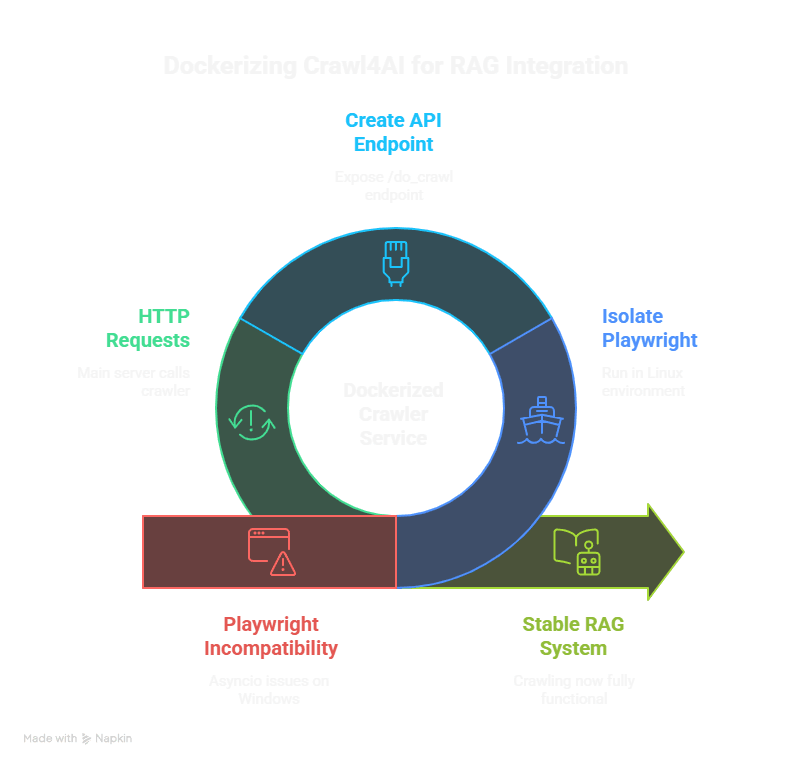
The Outcome (Backend Complete, Frontend Complete): We successfully implemented a powerful RAG backend and frontend! The key solution to the Playwright issue was to Dockerize the crawling component.
- Dockerized Crawler Service: A separate, minimal FastAPI service was created within a Docker container (crawl_service_docker). This service houses crawl4ai and its Playwright dependency, running in a stable Linux environment, thus bypassing the Windows asyncio issues. It exposes a simple /do_crawl endpoint.
-
Main FastAPI Server (fastapi_server):
- Refactored into modular APIRouters for TTS and the new RAG functionalities.
- The RAG ingestion endpoint (/rag/ingest) now calls the Dockerized crawler service via HTTP (using httpx) to fetch web content.
- Upon receiving scraped Markdown from the Docker service, the main FastAPI server's ingestion_orchestrator.py handles chunking (chunker_service.py), metadata extraction (metadata_service.py), and stores the data in a local ChromaDB instance (managed by chroma_service.py).
- A RAG query endpoint (/rag/query) uses retrieval_service.py to fetch relevant context from ChromaDB and answer_generation_service.py to formulate an answer using a configured LLM (currently defaulting to local Ollama).
- Functionality: The backend can now successfully ingest data from URLs/sitemaps and respond to queries based on that ingested data.
For the next major phase we built the "Crawl & RAG" page within the Electron/Vue3 application to provide a user interface for these new backend capabilities.
Key Learnings:
- Docker for Problematic Dependencies: When a library has deep-seated environmental conflicts (like Playwright with asyncio on Windows in certain contexts), Docker provides an excellent isolation layer to run it in a more compatible environment (e.g., Linux).
- Microservice Approach: Treating the crawler as a separate microservice (even if running locally via Docker) simplified the main FastAPI application and decoupled the problematic dependency.
- FastAPI APIRouters: Essential for keeping a growing FastAPI application organized and maintainable by splitting endpoints into logical modules.
- Python's multiprocessing for Long Tasks: While the final solution for crawling was Docker, the attempts to use multiprocessing for the Playwright-based ingestion (before Docker) highlighted its utility for offloading tasks that might block or have conflicting async requirements from the main FastAPI event loop. The ingestion within the Docker container itself runs Playwright in its own process.
- Clear API Contracts: Defining clear Pydantic models for requests and responses between the Electron app, the main FastAPI server, and the Dockerized crawler service was crucial for smooth integration.
- Persistence of Asyncio Issues: Sometimes, even explicit event loop policy settings aren't enough if a library's internals or the hosting framework (like Uvicorn on Windows) have their own strong opinions on loop management for subprocesses.
The "AI" Approach: My LLM assistant was a true partner through this complex integration. It helped:
- Outline the initial architecture for integrating crawl4AI into FastAPI.
- Refactor the crawl4AI-agent-v2 Python scripts into modular services.
- Draft Pydantic models for API request/response bodies.
- Brainstorm solutions for the Playwright/asyncio NotImplementedError, suggesting various event loop policies and process isolation techniques.
- Generate the initial Dockerfile and the minimal FastAPI app structure for the crawl_service_docker.
- Debug countless import errors, indentation issues, and logic flaws across the Python backend.
While the journey to get Playwright running smoothly was challenging, the Dockerized solution is robust. The backend is now primed to provide powerful RAG capabilities to the Electron desktop application. I'm excited to start using the frontend UI with my daily local LLM workflows!